Nesta postagem, apresento a resolução de 18 questões objetivas (componente específico) do ENADE 2017 de Ciência da Computação.

As resoluções são de minha autoria, pois o INEP não disponibiliza as soluções das questões objetivas. No final da postagem, deixarei links contendo as respostas oficiais das questões discursivas e o gabarito oficial da prova.
Índice
- Questões Resolvidas
- Referências
- Prova e Gabarito
Para mais questões do ENADE dos cursos de computação, acesse: ENADE.
Questão 09
Assunto: estruturas de dados. [Índice]
Uma árvore AVL é um tipo de árvore binária balanceada na qual a diferença entre as alturas de suas subárvores da esquerda e da direita não pode ser maior do que 1 para qualquer nó. Após a inserção de um nó em uma AVL, a raiz da subárvore de nível mais baixo no qual o novo nó foi inserido é marcada. Se a altura de seus filhos diferir em mais de uma unidade, é realizada uma rotação simples ou uma rotação dupla para igualar suas alturas.
LAFORE, R. Data Structures & algorithms in Java. Indianópolis: Sams Publishing, 2003 (adaptado).
A seguir, é apresentado um exemplo de árvore AVL.
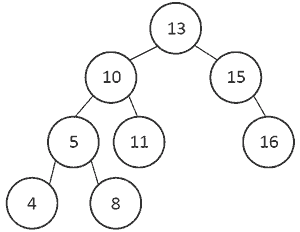
Pelo exposto no texto acima, após a inserção de um nó com valor 3 na árvore AVL exemplificada, é correto afirmar que ela ficará com a seguinte configuração
- (A)

Alternativa A - (B)

Alternativa B - (C)

Alternativa C - (D)

Alternativa D - (E)

Alternativa E
Resolução
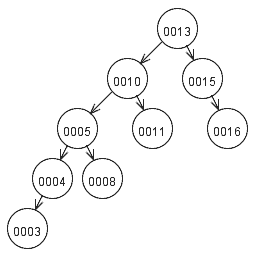
Ao inserir o nó de valor 3, sem se preocupar com o balanceamento, a árvore ficará da seguinte forma
Após a inserção, o nó 10 desbalanceou. Para balanceá-lo, devemos aplicar uma rotação simples à direita. O GIF animado a seguir ilustra a rotação
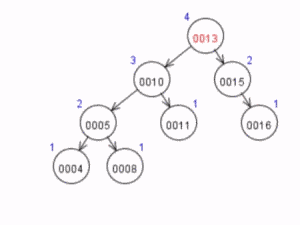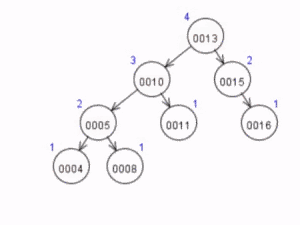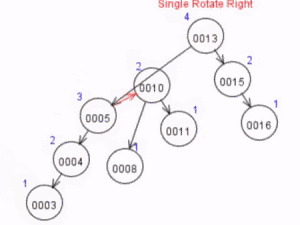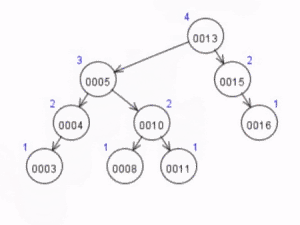
A árvore, após essa rotação, terá a seguinte forma

Portanto, a alternativa correta é a A.
Obsevação: as imagens da resolução da questão e o GIF animado foram gerados utilizando um visualizador de estruturas de dados que apresentei anteriormente no blog.
Questão 10
Assunto: engenharia de software. [Índice]
Considere os seguintes requisitos para desenvolvimento de uma solução para uma rede de restaurantes fast-food:
Quando o status de um pedido é atualizado, todos os dispositivos dos envolvidos devem receber a informação. Os sistemas a ser atualizados incluem os acessados pelo entregador, pela linha de produção e pela central de atendimento. Espera-se ainda que outros sistemas possam ser incluídos futuramente (por exemplo, sistema de pedido on-line do cliente), devendo se comportar da mesma forma.
Considerando esse contexto, avalie as asserções a seguir e a relação proposta entre elas.
I. O requisito apresentado pode ser implementado com a utilização do padrão de projeto Observer.
PORQUE
II. O padrão de projeto Observer realiza o estilo arquitetural cliente-servidor, no qual o servidor é responsável por enviar notificações aos clientes sempre que houver atualização em alguma informação de interesse.
A respeito dessas asserções, assinale a opção correta.
- (A) As asserções I e II são proposições verdadeiras, e a II é uma justificativa correta da I.
- (B) As asserções I e II são proposições verdadeiras, mas a II não é uma justificativa correta da I.
- (C) A asserção I é uma proposição verdadeira, e a II é uma proposição falsa.
- (D) A asserção I é uma proposição falsa, e a II é uma proposição verdadeira.
- (E) As asserções I e II são proposições falsas.
Resolução
A asserção I é verdadeira. A implementação poderia ser feita da seguinte forma: o pedido é o objeto que está sendo "observado" (Subject), os dispositivos são os "observadores" (Observer). Sempre que o objeto pedido sofrer alguma mudança no seu estado, um método ou função desse objeto deve ser acionado para notificar os dispositivos.
A asserção II é falsa:
"Em uma arquitetura cliente-servidor, a funcionalidade do sistema está organizada em serviços — cada serviço é prestado por um servidor. Os clientes são usuários desses serviços e acessam os servidores para fazer uso deles." (SOMMERVILLE, 2011)
Além disso, a arquitetura cliente-servidor é um padrão de arquitetura e o padrão Observer é um padrão de projeto para projetos de software orientado a objetos, isto é, a finalidade deles é bem distinta.
Portanto, a alternativa correta é a C.
Questão 11
Assunto: paradigmas de linguagens de programação. [Índice]
O encapsulamento é um mecanismo da programação orientada a objetos no qual os membros de uma classe (atributos e métodos) constituem uma caixa preta. O nível de visibilidade dos membros pode ser definido pelos modificadores de visibilidade "privado", "público" e "protegido".
Com relação ao comportamento gerado pelos modificadores de visibilidade, assinale a opção correta.
- (A) Um atributo privado pode ser acessado pelos métodos privados da própria classe e pelos métodos protegidos das suas classes descendentes.
- (B) Um atributo privado pode ser acessado pelos métodos públicos da própria classe e pelos métodos públicos das suas classes descendentes.
- (C) Um membro público é visível na classe à qual ele pertence, mas não é visível nas suas classes descendentes.
- (D) Um método protegido não pode acessar os atributos privados e declarados na própria classe.
- (E) Um membro protegido é visível na classe à qual pertence e em suas classes descendentes.
Resolução
As alternativas A e B estão incorretas, pois atributos privados de uma classe não podem ser acessados pelos métodos de suas classes descendentes, sejam eles públicos, protegidos ou privados.
A alternativa C está incorreta, pois um membro público pode ser acessado por qualquer classe.
A alternativa D está incorreta também, pois os atributos privados de uma classe podem ser acessados por qualquer método da própria classe.
A alternativa E está correta.
Questão 12
Assunto: arquitetura de computadores. [Índice]
Em um computador, a memória é a unidade funcional que armazena e recupera operações e dados. Tipicamente, a memória de um computador usa uma técnica chamada acesso aleatório, que permite o acesso a qualquer uma de suas posições (células). As memórias de acesso aleatório são divididas em células de tamanho fixo, estando cada célula associada a um identificador numérico único chamado endereço. Todos os acessos à memória referem-se a um endereço específico e deve-se sempre buscar ou armazenar o conteúdo completo de uma célula, ou seja, a célula é a unidade mínima de acesso.
SCHNEIDER, G. M.; GERSTING, J. L. An Invitation to computer science. 6 ed. Boston: MA: Course Technology, Cengage Learning, 2009 (adaptado).
A figura que segue apresenta a estrutura de uma unidade de memória de acesso aleatório

Considerando o funcionamento de uma memória de acesso aleatório, avalie as afirmações a seguir.
- I. Se a largura do registrador de endereços da memória for de 8 bits, o tamanho máximo dessa unidade de memória será de 256 células.
- II. Se o registrador de dados da memória tiver 8 bits, será necessário mais que uma operação para armazenar os valor inteiro 2024 nessa unidade de memória.
- III. Se o registrador de dados da memória tiver 12 bits, é possível que a largura de memória seja de 8 bits.
É correto o que se afirma em
- (A) I, apenas.
- (B) III, apenas.
- (C) I e II, apenas.
- (D) II e III, apenas.
- (E) I, II e III.
Resolução
A afirmação I é verdadeira. Um registrador de 8 bits permite até 28 endereços, isto é, 256 endereços possíveis. Consequentemente, o tamanho máximo da memória será de 256 células, pois teremos uma célula para cada endereço.
A afirmação II também é verdadeira, pois você precisa de pelo menos 11 bits para armazenar o número 2024, pois seu valor em binário é 11111101000. Ou seja, precisaríamos de no mínimo duas operações.
A afirmação III é a única que é falsa. Portanto, a alternativa correta é a C.
Questão 13
Assunto: circuitos digitais. [Índice]
Os sistemas de refrigeração de piscinas de combustível em usinas nucleares evitam que a temperatura desses tanques exceda o limite de segurança. O circuito representado na figura a seguir atende aos requisitos necessários para o controle da ativação do sistema de resfriamento quando a temperatura está próxima de seu ponto crítico.
O diagrama de tempo ilustrado na figura apresenta uma amostra das temperaturas lidas desde o momento t1 ao t8. Os sinais de entrada Ta, Tb e Tc são de termômetros que medem a temperatura da piscina em diferentes pontos ao longo do dia e S é o terminal de acionamento do sistema.
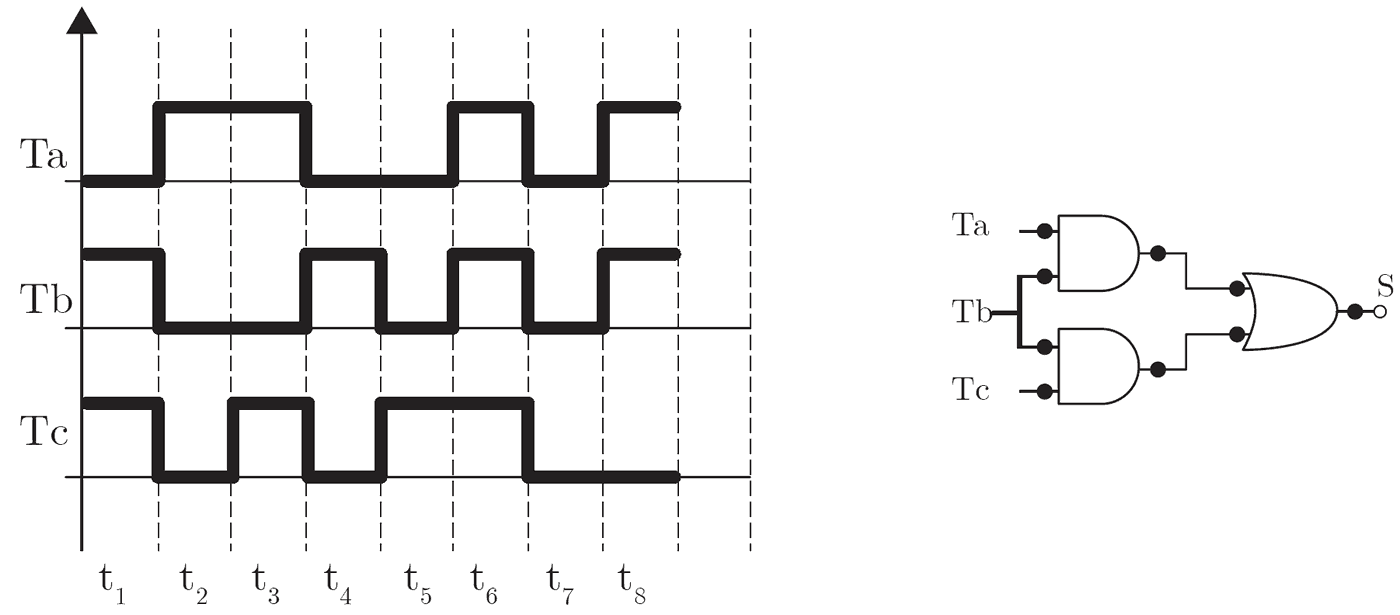
Nesse contexto, assinale a opção em que são apresentados os momentos em que o sistema foi acionado.
- (A) t1, t4 e t8.
- (B) t1, t6 e t8.
- (C) t2, t4 e t6.
- (D) t2, t6 e t8.
- (E) t3, t5 e t7.
Resolução
A expressão booleana desse circuito é dada a seguir
S = TaTb + Tb Tc
S = Tb(Ta + Tc)
A tabela a seguir indica o valor da saída S do circuito em cada momento
| Momento | Ta | Tb | Tc | S |
| t1 | 0 | 1 | 1 | 1 |
| t2 | 1 | 0 | 0 | 0 |
| t3 | 1 | 0 | 1 | 0 |
| t4 | 0 | 1 | 0 | 0 |
| t5 | 0 | 0 | 1 | 0 |
| t6 | 1 | 1 | 1 | 1 |
| t7 | 0 | 0 | 0 | 0 |
| t8 | 1 | 1 | 0 | 1 |
Observe que o circuito é acionado apenas em t1, t6 e t8. Portanto, a alternativa correta é a B.
Questão 14
Assunto: matemática. [Índice]
Uma relação de equivalência é uma relação binária $R$ em um conjunto $A$, tal que $R$ é reflexiva, simétrica e transitiva.
Considere as relações binárias apresentadas a seguir.
- $R1 =\{(a,b):a,b\in\mathbb{N}\,e\,a=b\};$
- $R2 =\{(a,b):a,b\in\mathbb{N}\,e\,a\leq b\};$
- $R3 =\{(a,b):a,b\in\mathbb{N}\,e\,a=b-1\};$
- $R4 =\{(a,b):a,b\in\mathbb{N}\,e\,a+b$ é um número par$\}$
São relações de equivalência apenas o que se apresenta em
- (A) $R2$ e $R3$.
- (B) $R1$ e $R3$.
- (C) $R1$ e $R4$
- (D) $R1$, $R2$ e $R4$
- (E) $R2$, $R3$ e $R4$
Resolução
As propriedades que uma relação de equivalência deve satisfazer são listadas a seguir
Reflexiva: Uma relação $R$ é reflexiva se todo elemento de $A$ está relacionado consigo mesmo, ou seja, para todo $x\in A:(x,x)\in R$ (SODRÉ, MARTINS, 2006).
Simétrica: Uma relação $R$ é simétrica se o fato que $x$ está relacionado com $y$, implicar necessariamente que $y$ está relacionado com $x$, ou seja: quaisquer que sejam $x\in A$ e $y\in A$ tal que $(x,y)\in R$, segue que $(y,x)\in R$ (SODRÉ, MARTINS, 2006).
Transitiva: Uma relação $R$ é transitiva, se $x$ está relacionado com $y$ e $y$ está relacionado com $z$, implicar que $x$ deve estar relacionado com $z$, ou seja: quaisquer que sejam $x, y, z\in A$, se $(x,y)\in R$ e $(y,z)\in R$ então $(x,z)\in R$ (SODRÉ, MARTINS, 2006).
As relações $R1$ e $R4$ satisfazem as três propriedades.
A relação $R2$ é reflexiva e transitiva, mas não é simétrica. Como exemplo, vamos supor que $a=2$ e $b=4$. Nesse caso, é verdade que $a\leq b$ ($2\leq 4$), mas não é verdade que $b\leq a$, pois 4 não é menor ou igual a 2.
A relação $R3$ não satisfaz nenhuma das três propriedades.
Observe que nenhum par do tipo $(a,a)$ pode fazer parte de $R3$, pois a expressão $a=a-1$ é sempre falsa.
Para provar que a relação não é simétrica, vamos considerar o par $(2,3)$, que faz parte da relação. Se $R3$ fosse simétrica, então o par $(3,2)$ também deveria pertencer à relação, contudo não é verdade que $3=2-1$, logo $R3$ não é simétrica.
Por fim, para provar que a relação não é transitiva, podemos utilizar os pares $(2,3)$ e $(3,4)$, pertencentes à $R3$. Pela propriedade transitiva, se $(2,3)\in R3$ e $(3,4)\in R3$, então $(2,4)$ também deveria pertencer à $R3$, porém isso não é verdade, pois é falso dizer que $2=4-1$.
Observação: se você provar que uma relação não satisfaz pelo menos uma das três propriedades (reflexiva, simétrica ou transitiva), então ela automaticamente não será uma relação de equivalência.
Logo, a alternativa correta é a C.
Questão 18
Assunto: algoritmos. [Índice]
O algoritmo a seguir recebe um vetor v de números inteiros e rearranja esse vetor de tal forma que seus elementos, ao final, estejam ordenados de forma crescente.
01 void ordena(int *v, int n)
02 {
03 int i, j, chave;
04 for(i = 1; i < n; i++)
05 {
06 chave = v[i];
07 j = i - 1;
08 while(j >= 0 && v[j] < chave)
09 {
10 v[j-1] = v[j];
11 j = j - 1;
12 }
13 v[j+1] = chave;
14 }
15 }
Considerando que nesse algoritmo há erros de lógica que devem ser corrigidos para que os elementos sejam ordenados de forma crescente, assinale a opção correta no que se refere às correções adequadas.
- (A) A linha 04 deve ser corrigida da seguinte forma:
for(i = 1; i < n - 1; i++)e a linha 13, do seguinte modo:v[j - 1] = chave;. - (B) A linha 04 deve ser corrigida da seguinte forma:
for(i = 1; i < n - 1; i++)e a linha 07, do seguinte modo:j = i + 1;. - (C) A linha 07 deve ser corrigida da seguinte forma:
j = i + 1e a linha 08, do seguinte modo:while(j >= 0 && v[j] > chave). - (D) A linha 08 deve ser corrigida da seguinte forma:
while(j >= 0 && v[j] > chave)e a linha 10, do seguinte modo:v[j + 1] = v[j]; - (E) A linha 10 deve ser corrigida da seguinte forma:
v[j + 1] = v[j];e a linha 13, do seguinte modo:v[j - 1] = chave;.
Resolução
Quem já leu os primeiros capítulos do livro Algoritmos: teoria e prática [1] deve ter notado que o algoritmo desta questão é uma versão na linguagem C do insertion sort analisado no livro.
No algoritmo, chave é o valor no qual devemos procurar a posição de inserção, que está entre o índice 0 e o índice i - 1. A busca é realizada no laço das linhas 8-12 e é feita da direita para a esquerda, a partir do índice i - 1.
Os valores maiores que chave são deslocados para a direita. Veja que a condição v[j] < chave está errada, pois está verificando se o valor é menor que a chave e não se é maior. Logo, o correto seria v[j] > chave.
Outro erro é encontrado na linha 10, que faz os deslocamentos para a esquerda e não para a direita. O correto, nesse caso, seria v[j + 1] = v[j].
Portanto, a alternativa correta é a D.
Questão 19
Assunto: banco de dados. [Índice]
Considere o diagrama Entidade-Relacionamento apresentado a seguir.

Qual código SQL exibe o nome de todos os deputados que compareceram a pelo menos uma seção e as datas de cada seção em que os deputados participaram?
- (A)
SELECT Deputado.nomeDeputado, Secao.dataSecao FROM Deputado, Participacao, Secao WHERE Deputado.idDeputado=Participacao.idDeputado; - (B)
SELECT Deputado.nomeDeputado, Secao.dataSecao FROM Deputado, Participacao, Secao WHERE Deputado.idDeputado = Participacao. idDeputado OR Secao.idSecao = Participacao.idSecao; - (C)
SELECT Deputado.nomeDeputado, Secao.dataSecao FROM Deputado LEFT OUTER JOIN Participacao ON Deputado.idDeputado = Participacao.idDeputado LEFT OUTER JOIN Secao ON Secao.idSecao = Participacao.idSecao; - (D)
SELECT Deputado.nomeDeputado, Secao.dataSecao FROM Deputado RIGHT OUTER JOIN Participacao ON Deputado.idDeputado = Participacao.idDeputado RIGHT OUTER JOIN Secao ON Secao.idSecao = Participacao.idSecao; - (E)
SELECT Deputado.nomeDeputado, Secao.dataSecao FROM Deputado INNER JOIN Participacao ON Deputado.idDeputado = Participacao.idDeputado INNER JOIN Secao ON Participacao.idSecao=Secao.idSecao;
Resolução
Para exibir os nomes dos deputados e as datas das seções que eles participaram, precisamos utilizar o INNER JOIN, pois exibiremos dados de tabelas distintas. Uma vez que as tabelas Deputado e Secao estão relacionadas através da tabela Participacao, então o JOIN será entre as três tabelas.
As alternativas C e D estão incorretas, pois utilizam o OUTER JOIN. O problema é que um OUTER JOIN exibirá dados além dos dados que precisamos, tais como deputados que nunca foram a uma seção ou seções sem deputados presentes. Os diagramas a seguir ilustram o funcionamento do LEFT OUTER JOIN e do RIGHT OUTER JOIN.

A alternativa A está incorreta porque está desprezando a tabela Secao na condição da cláusula WHERE. Para corrigir, precisaríamos acrescentar a seguinte condição Secao.idSecao = Participacao.idSecao, utilizando o operador AND.
A alternativa B está errada por causa a utilização do operador lógico OR ao invés de AND na condição da cláusula WHERE que relaciona as três tabelas.
Ou seja, a alternativa correta é a E.
Questão 20
Assunto: redes de computadores. [Índice]
Em redes de computadores, a camada de transporte é responsável pela transferência de dados entre máquinas de origem e destino. Dois protocolos tradicionais para essa camada são o Transmission Control Protocol (TCP) e User Datagram Protocol (UDP). Diferente do UDP, o TCP é orientado à conexão. Com relação a esses protocolos, avalie as afirmações a seguir.
- I. O UDP é mais eficiente que o TCP quando o tempo de envio de pacotes é fundamental.
- II. O TCP é o mais utilizado em jogos on-line de ação para a apresentação gráfica.
- III. O TCP é mais eficiente que o UDP quando a confiabilidade de entrega de dados é fundamental.
É correto o que se afirma em
- (A) II, apenas.
- (B) III, apenas.
- (C) I e II, apenas.
- (D) I e III, apenas.
- (E) I, II e II.
Resolução
A única afirmativa falsa é a II, pois a apresentação gráfica em um jogo não depende da conexão. Gráficos são processados pela GPU e exibidos ao usuário pelo monitor de vídeo. Isto é, não há participação da interface de rede.
Logo, a opção correta é a D.
Questão 22
Assunto: paradigmas de projeto de algoritmos. [Índice]
Um país utiliza moedas de 1, 5, 10, 25 e 50 centavos. Um programador desenvolveu o método a seguir, que implementa a estratégia gulosa para o problema do troco mínimo. Esse método recebe como parâmetro um valor inteiro, em centavos, e retorna um array no qual cada posição indica a quantidade de moedas de cada valor.
public static int[] troco(int valor){
int[] moedas = new int[5];
moedas[4] = valor / 50;
valor = valor % 50;
moedas[3] = valor / 25;
valor = valor % 25;
moedas[2] = valor / 10;
valor = valor % 10;
moedas[1] = valor / 5;
valor = valor % 5;
moedas[0] = valor;
return moedas;
}
Considerando o método apresentado, avalie as asserções a seguir e a relação proposta entre elas.
I. O método guloso encontra o menor número de moedas para o valor de entrada, considerando as moedas do país.
PORQUE
II. Métodos gulosos sempre encontram a solução ótima global.
A respeito dessas asserções, assinale a opção correta.
- (A) As asserções I e II são proposições verdadeiras, e a II é uma justificativa correta da I.
- (B) As asserções I e II são proposições verdadeiras, mas a II não é uma justificativa correta da I.
- (C) A asserção I é uma proposição verdadeira, e a II é uma proposição falsa.
- (D) A asserção I é uma proposição falsa, e a II é uma proposição verdadeira.
- (E) As asserções I e II são proposições falsas.
Resolução
A asserção I está correta, uma vez que o algoritmo inicia a contagem a partir das moedas de maior valor, isto é, da moeda de maior valor até a moeda de menor valor.
A asserção II é falsa, pois nem sempre métodos gulosos fornecem uma solução ótima global:
"Um algoritmo guloso sempre faz a escolha que parece ser a melhor no momento em questão. Isto é, faz uma escolha localmente ótima, na esperança de que essa escolha leve a uma solução globalmente ótima." (CORMEN et al, 2012)
Isto é, nem sempre um algoritmo guloso encontra a solução ótima de um problema [1].
Portanto, a alternativa correta é a C.
Questão 23
Assunto: linguagens formais e autômatos. [Índice]
Considere o seguinte alfabeto
$$\Sigma=\{(,),0,1,2,3,4,5,6,7,8,9,+,-\}.$$
Considere, ainda, uma linguagem $L$ definida sobre esse alfabeto.
$L = \{w | w \in\Sigma^{*}$, para cada ocorrência de '$($' em $w$, existe uma ocorrência de '$)$'$\}$
Por exemplo, a cadeia $x=(2+(3-4))$ pertence a $L$, mas a cadeia $y = (2+(3-4)$ não pertence a $L$.
Com relação à linguagem $L$, avalie as asserções a seguir e a relação proposta entre elas.
I. A linguagem $L$ não pode ser considerada regular.
PORQUE
II. Autômatos finitos não possuem mecanismos que permitam contar infinitamente o número de ocorrências de determinado símbolo em uma cadeia.
A respeito dessas asserções, assinale a opção a opção correta.
- (A) As asserções I e II são proposições verdadeiras, e a II é uma justificativa correta da I.
- (B) As asserções I e II são proposições verdadeiras, mas a II não é uma justificativa correta da I.
- (C) A asserção I é uma proposição verdadeira, e a II é uma proposição falsa.
- (D) A asserção I é uma proposição falsa, e a II é uma proposição verdadeira.
- (E) As asserções I e II são proposições falsas.
Resolução
A asserção I é verdadeira, pois $L$ é uma linguagem livre de contexto devido à necessidade de haver o balanceamento entre os parênteses.
A asserção II também é verdadeira e justifica corretamente a asserção I. Para realizar a contagem de símbolos da cadeia, precisaríamos de memória extra para registrar a ocorrência de cada símbolo, algo ausente nos autômatos finitos. Tal deficiência é suprida pela pilha dos autômatos a pilha. Isso faz todo sentido quando levamos em conta que $L$ é livre de contexto e que essa classe de linguagens é reconhecida por autômatos a pilha.
Portanto, a alternativa correta é a A.
Questão 24
Assunto: teoria dos grafos. [Índice]
A figura a seguir exibe um grafo que representa um mapa rodoviário, no qual os vértices representam cidades e as arestas representam vias. Os pesos indicam o tempo atual de deslocamento entre duas cidades.
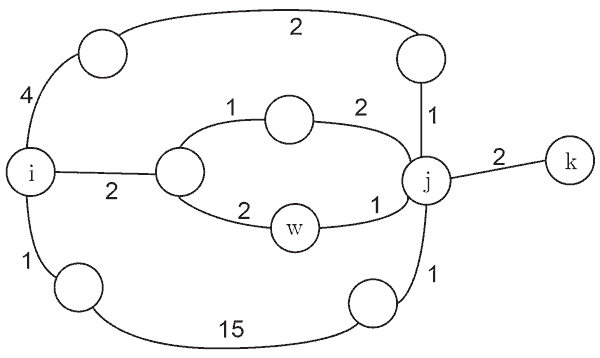
Considerando que os tempos de ida e volta são iguais para qualquer via, avalie as afirmações a seguir acerca desse grafo.
- I. Dado o vértice de origem
i, o algoritmo de Dijkstra encontra o menor tempo de deslocamento entre a cidadeie todas as demais cidades do grafo. - II. Uma árvore geradora de custo mínimo gerada pelo algoritmo de Kruskal contém um caminho de custo mínimo cuja origem é
ie cujo destino ék. - III. Se um caminho de custo mínimo entre os vértices
iekcontém o vérticew, então o subcaminho de origemwe destinokdeve também ser mínimo.
É correto o que se afirma em
- (A) I, apenas.
- (B) II, apenas.
- (C) I e III, apenas.
- (D) II e III, apenas.
- (E) I, II e III.
Resolução
A afirmação I está correta. Ela basicamente descreve o que o algoritmo de Dijkstra faz.
A afirmação II está correta. A árvore geradora de custo mínimo a seguir foi gerada através do algoritmo de Kruskal e possui um caminho mínimo (está destacado na imagem)
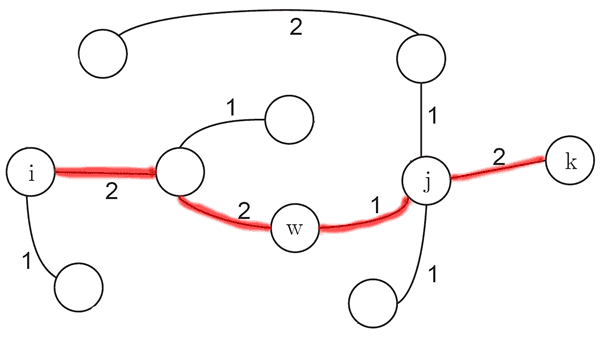
A afirmação III também está correta e é provada graças a um lema que diz que "subcaminhos de caminhos mínimos são caminhos mínimos" [1]. Esse é o princípio explorado pelos algoritmos de caminhos mínimos.
Portanto, a alternativa correta é a E.
Questão 25
Assunto: complexidade de algoritmos. [Índice]
A sequência de Fibonacci é uma sequência de números inteiros que começa em 1, a que se segue 1, e na qual cada elemento subsequente é a soma dos dois elementos anteriores. A função fib a seguir calcula o n-ésimo elemento da sequência de Fibonacci:
unsigned int fib (unsigned int n)
{
if (n < 2)
return 1;
return fib(n - 2) + fib(n - 1);
}
Considerando a implementação acima, avalie as afirmações a seguir.
- I. A complexidade de tempo da função
fibé exponencial no valor den. - II. A complexidade de espaço da função
fibé exponencial no valor den. - III. É possível implementar uma versão iterativa da função
fibcom complexidade de tempo linear no valor dene complexidade de espaço constante.
É correto o que se afirma em
- (A) I, apenas.
- (B) II, apenas.
- (C) I e III, apenas.
- (D) II e III, apenas.
- (E) I, II e III.
Resolução
A questão é fácil, pois o algoritmo é um dos mais populares entre os que estudam computação.
A afirmação I é verdadeira, pois essa versão recursiva do algoritmo de Fibonacci é $O(2^n)$ no tempo.
A afirmação II é falsa. Observe que não há alocação de memória no algoritmo. Na prática, a única memória consumida é a da pilha de chamadas recursivas.
A afirmação III é verdadeira. Utilizando a programação dinâmica, é possível escrever um algoritmo que atende aos requisitos da afirmação. Você pode consultar o algoritmo em A Sequência de Fibonacci: algoritmos em Java e C (é o algoritmo iterativo).
Portanto, a alternativa correta é a C.
Questão 26
Assunto: computação gráfica. [Índice]
A figura a seguir mostra uma imagem de ressonância magnética corrompida por ruído do tipo "sal e pimenta".

Para que o ruído seja atenuado e as bordas das estruturas representadas sejam preservadas, deve-se aplicar na imagem o filtro
- (A) Sobel.
- (B) da média.
- (C) Laplaciano.
- (D) do mínimo.
- (E) da mediana.
Resolução
Dos filtros listados, o único capaz de atenuar o ruído sal e pimenta é o filtro da mediana, pois, além de atenuar o ruído, ele é capaz de preservar detalhes da imagem, como as bordas [5].
O funcionamento do filtro é similar ao filtro da média, porém, ao invés de substituir o valor de um pixel pela média dos valores dos pixels adjacentes, o filtro da mediana substitui o valor do pixel pela mediana dos valores dos pixels adjacentes [5].
Portanto, a alternativa correta é a E.
Questão 27
Assunto: computação gráfica. [Índice]
Em computação gráfica, existem vários modelos de iluminação diferentes que expressam e controlam os fatores que determinam a cor de uma superfície em função de um determinado conjunto de luzes. Uma vez definido um modelo de iluminação, pode-se aplicar a luz sobre as várias faces dos objetos de uma cena, processo denominado sombreamento.
As figuras a seguir ilustram a aplicação de dois modelos de iluminação, a saber: o modelo de sombreamento constante (à esquerda) e o modelo de Phong (à direita).
AZEVEDO, E.; CONCI, A. Computação gráfica: geração de imagens. Rio de Janeiro: Campus, 2003 (adaptado).

Em relação aos modelos de iluminação apresentados, avalie as afirmações a seguir.
- I. A aplicação do modelo de sombreamento constante causa na imagem um efeito visual denominado Bandas de Mach.
- II. Embora seja útil para gerar imagens realísticas, o modelo de Phong mostra-se pouco eficiente na apresentação das reflexões especulares.
- III. O modelo de sombreamento constante não é útil para gerar imagens realísticas porque ele dá destaque ao aspecto facetado da representação poliedral das superfícies.
- IV. Para a utilização do modelo de Phong, é necessário supor que a fonte de luz localiza-se no infinito.
É correto apenas o que se afirma em
- (A) I e II.
- (B) I e III.
- (C) II e IV.
- (D) I, III e IV.
- (E) II, III e IV.
Resolução
As afirmações I e III estão corretas. O "aspecto facetado" mencionado em III é justamente o efeito Bandas de Mach mencionado em I. Esse efeito destaca a descontinuidade das cores ao longo dos polígonos que compõem a superfície do objeto tridimensional [4].
Observe na imagem à esquerda que a variação de tons em alguns polígonos adjacentes é abrupta. Naturalmente, o modelo de sombreamento constante não é indicado para gerar imagens realísticas.
A afirmação II é falsa. Além de ser eficiente, o modelo de Phong é um dos mais utilizados [4].
A afirmação IV é, definitivamente, falsa. Portanto, a alternativa correta é a B.
Um livro de computação gráfica que faz uma boa abordagem sobre o tema é Computação Gráfica: Teoria e Prática por Aura Conci e Eduardo Azevedo.
Questão 28
Assunto: engenharia de software. [Índice]
Os métodos ágeis são fundamentados no desenvolvimento e entrega incremental tendo em vista atender aos requisitos dos clientes. Eles agregam um conjunto de princípios provenientes do manifesto ágil, tais como:
- envolvimento do cliente;
- entrega incremental;
- pessoas, não processos;
- aceitação das mudanças;
- manutenção da simplicidade.
O Scrum é um exemplo de método ágil de gerenciamento de projetos. Avalie as afirmações a seguir sobre a relação do Scrum com os princípios do manifesto ágil.
- I. O Scrum adota a entrega incremental por meio de Sprints.
- II. O Scrum adota a simplicidade por meio do uso da programação em pares.
- III. O Scrum adota o envolvimento do cliente com a priorização e a negociação dos requisitos na concepção de Sprints.
É correto o que se afirma em
- (A) II, apenas.
- (B) III, apenas.
- (C) I e II, apenas.
- (D) I e III, apenas.
- (E) I, II e III.
Resolução
A afirmação I está correta. No Scrum, a cada Sprint, uma funcionalidade/incremento do sistema é entregue ao cliente [2].
A afirmação II está incorreta, pois
"Scrum não prescreve o uso de práticas de programação, como programação em pares e desenvolvimento test-first" (SOMMERVILLE, 2011).
A afirmação III está correta. Na fase de avaliação de um Sprint, o cliente pode, por exemplo, incluir novos requisitos e tarefas [2]. Já na etapa de seleção de um Sprint, o cliente e a equipe do projeto decidem juntos quais funcionalidades e recursos serão desenvolvidos naquele Sprint [2].
Portanto, a alternativa correta é a D.
Questão 30
Assunto: compiladores. [Índice]
Em um compilador, um analisador sintático descendente preditivo pode ser implementado com o auxílio de uma tabela construída a partir de uma gramática livre de contexto. Essa tabela, chamada tabela LL(k), indica a regra de produção a ser aplicada olhando-se o k-ésimo próximo símbolo lido, chamado lookahead(k). Por motivo de eficiência, normalmente busca-se utilizar k=1. Considere a gramática livre de contexto $G=(X,Y,Z, a, b,c,d,e,P,X)$, em que $P$ é composto pelas seguintes regras de produção:
$$\begin{align*}X&\rightarrow aZbXY\,|\,c\\Y&\rightarrow dX\,|\,\varepsilon\\Z&\rightarrow e\end{align*}$$
Considere, ainda, a seguinte tabela LL(1), construída a partir da gramática $G$, sendo $\$$ o símbolo que representa o fim da cadeia. Essa tabela possui duas produções distintas na célula $(Y, d)$, gerando, no analisador sintático, uma dúvida na escolha da regra de produção aplicada em determinados momentos da análise.
| a | b | c | d | e | $\$$ | |
| X | X → aZbXY | X → c | ||||
| Y | Y → dX Y → ε |
Y → ε | ||||
| Z | Z → e |
Considerando que o processo da construção dessa tabela LL(1), a partir da gramática $G$, foi seguido corretamente, a existência de duas regras de produção distintas na célula $(Y,d)$, neste caso específico, resulta
- (A) da ausência do símbolo de fim de cadeia ($\$$) nas regras de produção.
- (B) de um não-determinismo causado por uma ambiguidade na gramática.
- (C) do uso incorreto do símbolo de cadeia vazia (ε) nas regras de produção.
- (D) da presença de duas regras de produção com um único terminal no corpo.
- (E) da presença de duas regras de produção com o mesmo não terminal na cabeça.
Resolução
A alternativa correta é a B. Para mostrar que a gramática é ambígua, vamos derivar a cadeia $aebaebcdc$
$$\begin{align*}X&\vdash aZbXY\\&\vdash aebXY\\&\vdash aebaZbXYY\\&\vdash aebaebXYY\\&\vdash aebaebcYY\end{align*}$$
A partir dessa última forma sentencial, podemos continuar a derivação de duas formas.
Primeira forma:
$$\begin{align*}aebaebcYY &\vdash aebaebcdXY\\&\vdash aebaebcdcY\\&\vdash aebaebcdc\end{align*}$$
Segunda forma:
$$\begin{align*}aebaebcYY &\vdash aebaebcY \\&\vdash aebaebcdX\\&\vdash aebaebcdc\end{align*}$$
As árvores de derivação são apresentadas a seguir


Como a sentença $aebaebcdc$ possui mais de uma derivação, então a gramática é ambígua.
Questão 33
Assunto: complexidade de algoritmos. [Índice]
Considere a função recursiva F a seguir, que em sua execução chama a função G
1 void F(int n) {
2 if(n > 0) {
3 for(int i = 0; i < n; i++) {
4 G(i);
5 }
6 F(n/2);
7 }
8 }
Com base nos conceitos de teoria da complexidade, avalie as afirmações a seguir.
- I. A equação de recorrência que define a complexidade da função
Fé a mesma do algoritmo clássico de ordenação mergesort. - II. O número de chamadas recursivas da função
Fé $\Theta(\log n)$. - III. O número de vezes que a função
Gda linha 4 é chamada é $O(n\log n)$.
É correto o que se afirma em
- (A) I, apenas.
- (B) II, apenas.
- (C) I e III, apenas.
- (D) II e III, apenas.
- (E) I, II e III.
Resolução
Par analisar a primeira afirmação, precisamos obter a equação de recorrência da função F.
Primeiramente, observe que o laço da linha 3 realiza n iterações, logo a complexidade do laço é $\Theta(n)$ ou $O(n)$. A cada chamada da função F(n), temos uma chamada recursiva F(n/2), isto é, o problema é reduzido pela metade. Portanto, a equação de recorrência de F é $T(n)=T(n/2)+\Theta(n)$, que é diferente da recorrência do mergesort, que é $T(n)=2T(n/2)+\Theta(n)$. Logo, a afirmativa I é falsa.
A afirmativa II é verdadeira. A cada chamada de F, o valor de n é reduzido pela metade. Na k-ésima chamada, teremos F(n/2k). Tomando o caso base n = 1, teremos
$$\begin{align*}F\left(\frac{n}{2^k}\right)=F(1)\\\frac{n}{2^k}=1\\n=2^k\\k =\log_2 n\end{align*}$$
Como $\log_2 n$ é $\Theta(\log_2 n)$, então concluímos que a afirmação II está correta.
A afirmação III requer certa sutileza na análise. A quantidade de vezes que a função G é chamada é igual ao número de iterações realizadas no laço da linha 3, ou seja, n vezes para cada chamada individual de F(n).
Em síntese, na primeira chamada recursiva, G é executada n vezes, na segunda chamada, G será executada $\left\lfloor\cfrac{n}{2}\right\rfloor$ vezes, depois $\left\lfloor\cfrac{n}{2^2}\right\rfloor$ vezes e assim sucessivamente. Na última chamada na qual o laço é executado, apenas uma iteração será realizada.
Portanto, o número total de vezes que G é executada é representado pela soma
$$\begin{align*}S&=n + \left\lfloor\frac{n}{2}\right\rfloor + \left\lfloor\frac{n}{2^2}\right\rfloor + \left\lfloor\frac{n}{2^3}\right\rfloor + \ldots+1\\&=\sum_{i=0}^k \left\lfloor\frac{n}{2^i}\right\rfloor\end{align*}$$
O valor de k é o número de chamadas de F, que é $\lfloor\log_2 n\rfloor$:
$$S=\sum_{i=0}^{\lfloor\log_2 n\rfloor}\left\lfloor\frac{n}{2^i}\right\rfloor$$
Podemos fazer uma aproximação, se removermos os pisos
$$\begin{align*}S&\approx\sum_{i=0}^{\log_2 n}\frac{n}{2^i}\\&=n\sum_{i=0}^{\log_2 n}\left(\frac{1}{2}\right)^i\\&=n\times\frac{\left(\frac{1}{2}\right)^{\log_2 n + 1}-1}{\frac{1}{2} - 1}\\&=2n-1\\&=O(n)\end{align*}$$
A aproximação é exata para valores de n que sejam potências inteiras de 2.
Outra forma de obter o resultado anterior é resolvendo a equação de recorrência de F(n): $T(n)=T(n/2) +\Theta(n)$. Essa recorrência pode ser resolvida via teorema mestre ou método de Akra-Bazzi e tem como solução $T(n)=\Theta(n)$, que implica em $T(n)=O(n)$.
A afirmação III diz que G é executada $O(n\log n)$ vezes. Como a função $n\log n$ é assintoticamente maior que $n$,então $n=O(n\log n)$, portanto afirmação III está certa.
Logo, a alternativa correta é a D.
Referências
- [1] CORMEN, T. H. et al. Algoritmos: teoria e prática. 3 ed. Rio de Janeiro: Elsevier, 2012.
- [2] SOMMERVILLE, I. Engenharia de Software. 9 ed. São Paulo: Pearson Prentice Hall, 2011.
- [3] SODRÉ, U.; MARTINS, R. M. (2006). ENSINO MÉDIO :: Relações e Funções.
- [4] AZEVEDO, E.; CONCI, A. Computação Gráfica: Teoria e Prática. Rio de Janeiro: Elsevier, 2007.
- [5] FISHER R.; PERKINS S.; WALKER A.; WOLFART E. (2003). Median Filter. Acesso em 27 de março 2018.
Prova e Gabarito
Os links a seguir contêm o caderno de questões, o gabarito oficial e as soluções oficiais das questões discursivas.
Boa noite.
ResponderExcluirPoderiam explicar a resolução da questão 05 ENADE 2017 Ciência da Computação Bacharel por favor? Não estou conseguindo entender
Vamos lá. O texto fala do hidrogel, que é um material capaz de reter água e tornar viável a agricultura me regiões mais secas.
ExcluirA questão quer que você assinale a alternativa correta e para isso você tem que ler o texto.
Alternativa A é FALSA, pois o hidrogel não propicia a mortalidade de pés de café na estiagem.
Alternativa B é FALSA, pois o hidrogel pode ser utilizado em qualquer tipo de solo, embora o foco sejam solos áridos.
A alternativa C é VERDADEIRA e é a correta.
A alternativa D é FALSA, pois conforme o texto afirma o hidrogel natural não é comercialmente viável.
A alternativa E é FALSA, pois o hidrogel tem como função reter a água e ir liberando aos poucos para a planta, então se não há algum tipo de irrigação ou chuva (ainda que pouca), então o hidrogel simplesmente não funciona.
Portanto, a alternativa correta é a C.
nada sobre a questão 29?
ResponderExcluirA resposta, de acordo com o gabarito, é a alternativa E. Porém eu não sei resolver. Infelizmente, a minha disciplina de Sistemas Operacionais foi bem fraca na faculdade =/
Excluir